
Installer ton IA local même sur un PC qui date
Ton ordinateur commence peut-être à montrer quelques signes de fatigue, mais l’idée de renoncer à un outil puissant comme une Intelligence Artificielle Générative (IA) est loin d’être envisageable. Si tu es lassé des services cloud qui nécessitent une connexion constante, sont sensibles aux coûts récurrents, ou si tu es soucieux de la confidentialité de tes données, j’ai la solution idéale.
Google vient de rendre disponible Gemma 4, un modèle de langage léger et extrêmement performant. La meilleure nouvelle ? Il est conçu pour tourner efficacement même sur du matériel non dernier cri. Dans ce guide complet, on va apprendre à installer et à exécuter Gemma 4 localement sur ton système Linux, en utilisant l’outil indispensable : Ollama.
*Ce tutoriel est rédigé avec une base Arch Linux, mais les principes sont universels ; adapte simplement les paquets si tu utilises Ubuntu, Fedora, ou autre.*
🚀 Étape 1 : Préparer le terrain – Installer Ollama
Qu’est-ce qu’Ollama ? Ollama est ton gestionnaire de modèles. Il simplifie énormément le processus pour télécharger, exécuter et gérer des dizaines de LLMs populaires (comme Gemma, Llama, etc.) en ligne de commande.
Installation de Ollama :
Ouvre ton terminal et exécute la commande suivante pour télécharger et installer le script :
curl -fsSL https://ollama.com/install.sh | shVérification de l’installation :
Pour être sûr qu’Ollama est bien installé et accessible dans ton système :
ollama --versionDémarrage du Service :
Il est crucial que le service tourne en arrière-plan pour que tes applications puissent y accéder. Lance simplement :
ollama serve(Laisse cette fenêtre terminal ouverte ou lance ce processus en background pour le moment.)
🧠 Étape 2 : Télécharger et Tester les Modèles IA Locaux
Maintenant que le moteur est en place, on va y injecter le cerveau !
1. Télécharger Gemma 4 :
C’est notre modèle phare. Télécharge la version recommandée pour commencer :
ollama pull gemma4:e4b2. (Optionnel mais recommandé) Ajouter un Modèle de Sécurité :
Pour ne pas dépendre d’une seule source, télécharger un modèle alternatif est une excellente pratique. On ajoute ici Qwen :
ollama pull qwen:4b3. Premier Test de Conversion :
Testons immédiatement notre installation. Lance une conversation interactive avec Gemma 4.
ollama run gemma4:e4bDès que le prompt apparaît, pose une question test, par exemple : « Qu’est-ce qu’un Grand Modèle de Langage (LLM) ? Explique-le simplement. »
💡 Conseil Pro : Une fois le test réussi, tu peux quitter le prompt (avec /bye).
💻 Étape 3 : Passer du Terminal à l’Interface Graphique (AnythingLLM)
Utiliser la ligne de commande est puissant, mais pour une expérience de travail quotidienne, une interface graphique (GUI) est indispensable. C’est là qu’intervient AnythingLLM.
Prérequis Système :
AnythingLLM nécessite une bibliothèque de gestion de fichiers (libfuse) pour fonctionner correctement sur ton système :
# Sur Arch/Manjaro :
sudo pacman -S fuse2Téléchargement et Installation de AnythingLLM :
Télécharge et exécute l’installeur :
# 1. Télécharger l'installeur
curl -fsSL https://cdn.anythingllm.com/latest/installer.sh -o installer.sh
# 2. Rendre le script exécutable
chmod +x installer.sh
# 3. Lancer l'installation
./installer.shLancement de l’Application :
Une fois l’installation terminée, lance l’application :
./AnthingLLM*.AppImage🎉 Conclusion : Tu es équipé pour l’avenir de l’IA !
Félicitations ! Tu as réussi à installer un écosystème d’IA de pointe fonctionnant entièrement en local. L’interface graphique vient de se lancer, te permettant de connecter tes documents, de créer des bases de connaissances et de discuter avec ton modèle puissant (Gemma 4).
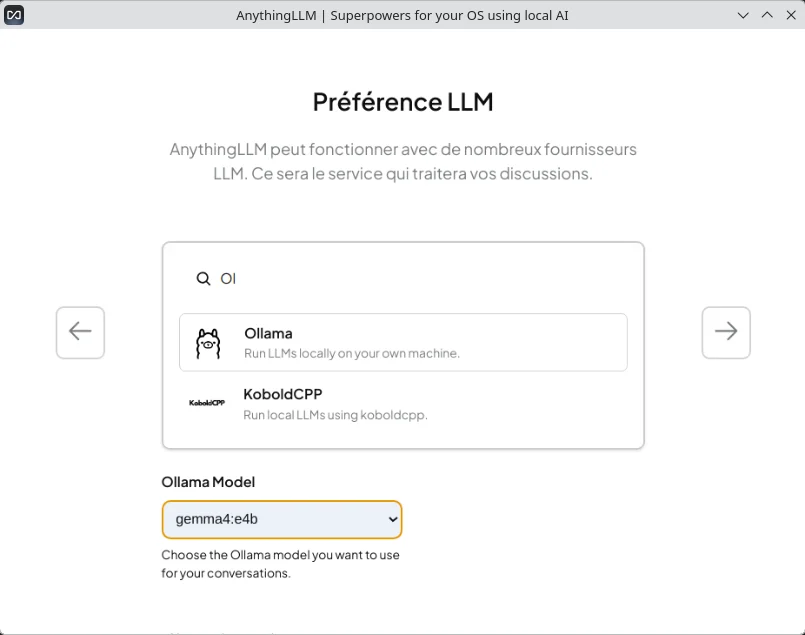
Maintenant, il ne reste plus qu’à explorer l’interface visuelle pour personnaliser ton environnement.
En résumé, tu as les joies du LLM ! Au revoir les limites de connexion et bonjour la confidentialité et la puissance illimitée de l’IA locale.


